읽기 전
- 불필요한 코드나 잘못 작성된 내용에 대한 지적은 언제나 환영합니다.
- 개인적으로 사용해보면서 배운 점을 정리한 글입니다.
플로이드-워셜 알고리즘이란?
플로이드 워셜 알고리즘은 그래프에서 가능한 모든 정점에 대해 최단거리를 구하는 알고리즘이다. 다익스트라 알고리즘은 V번 수행도 가능은 하나 코드 구현 측면에서 조금 더 복잡하며 일반적으로 다익스트라 알고리즘의 시간복잡도는 $O(Elog\ V)$로 표현되는데 V번 수행하므로 $O(VElog\ V)$가 되어 플로이드 워셜보다 불리해진다.
플로이드-워셜 알고리즘의 동작
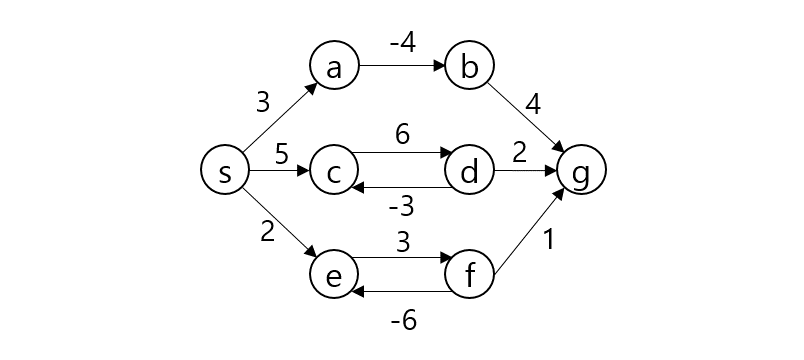
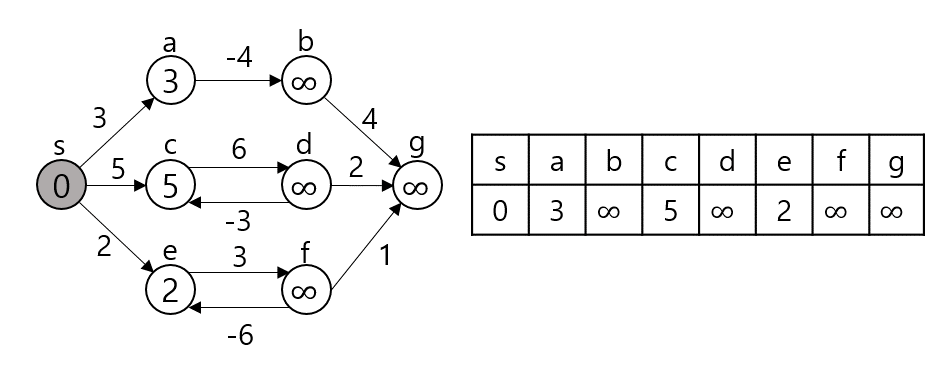
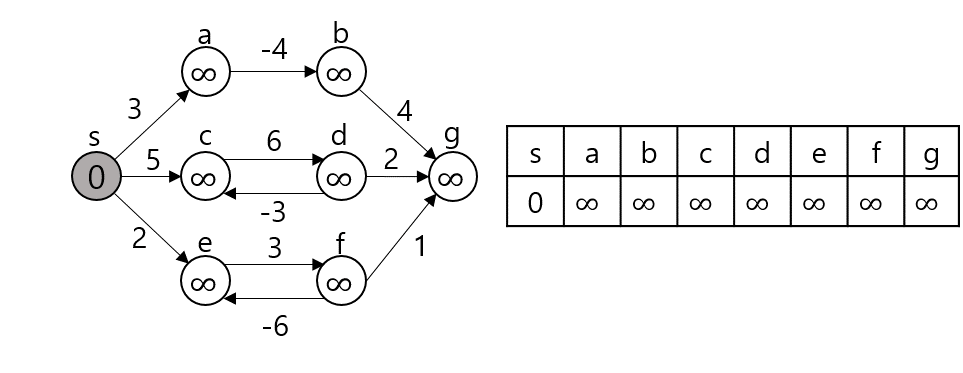
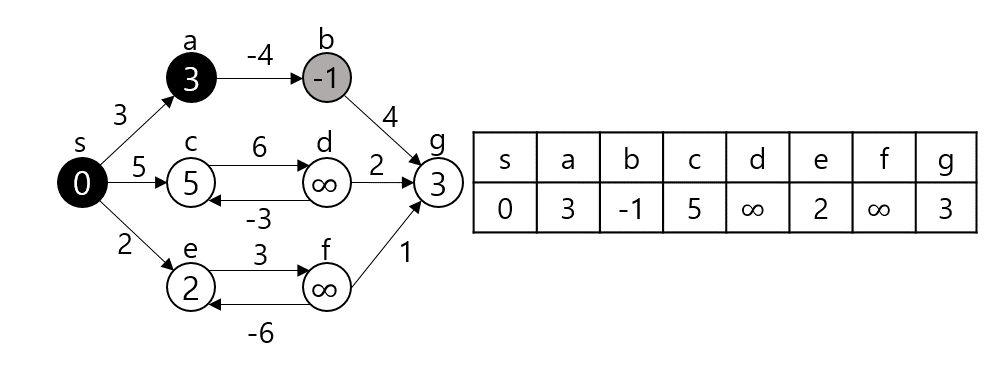
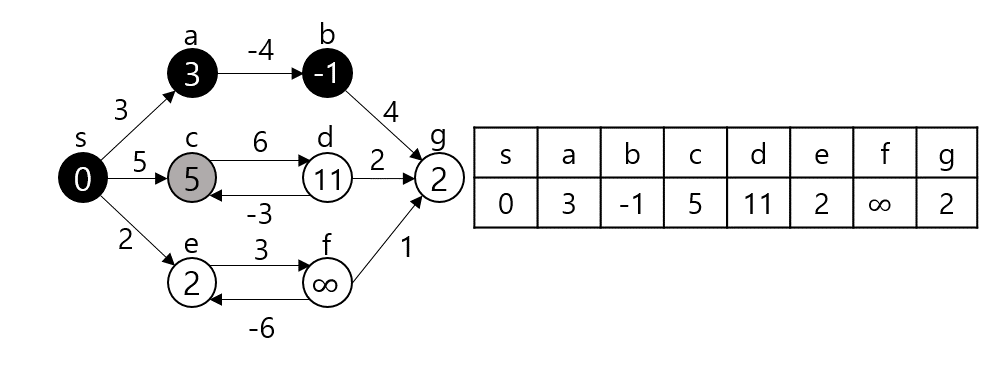
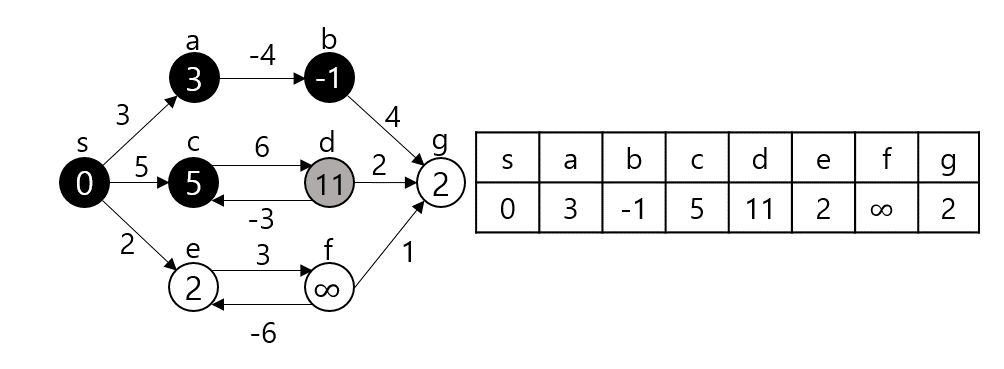
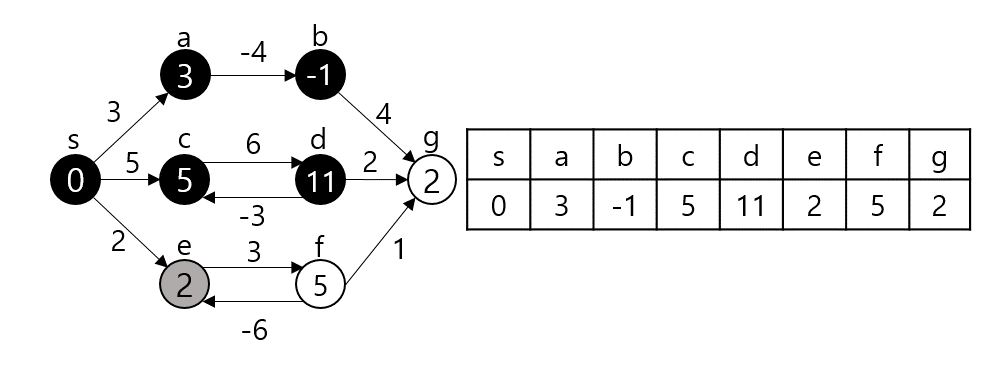
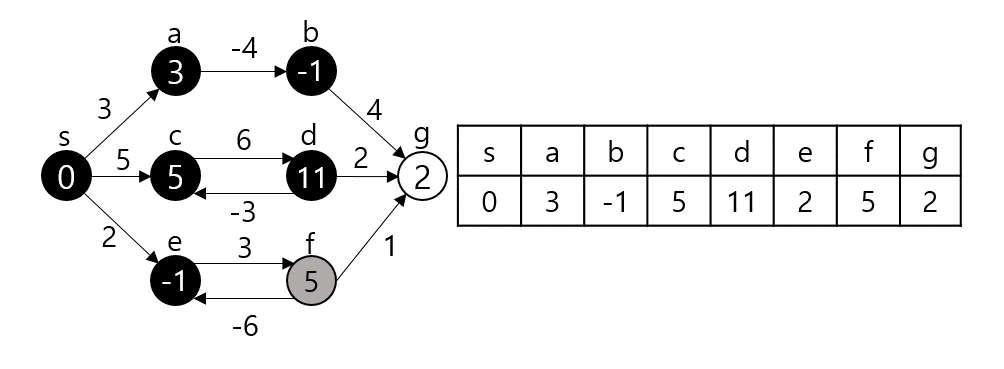
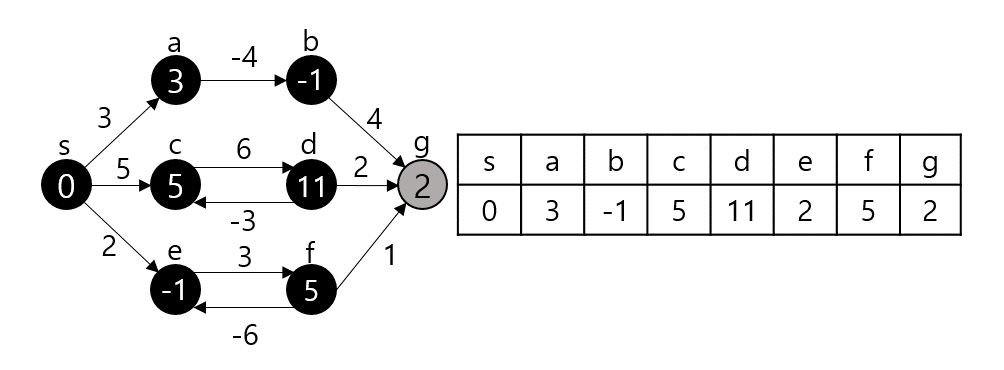
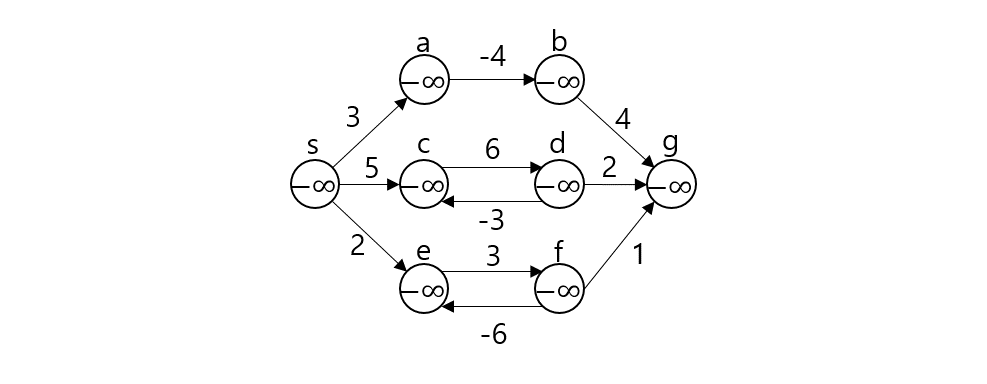
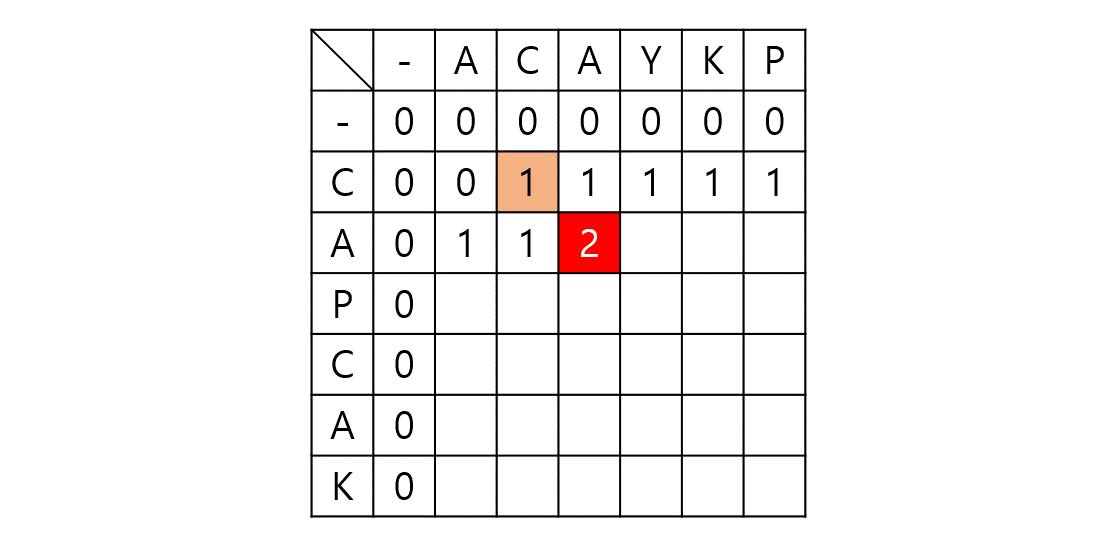
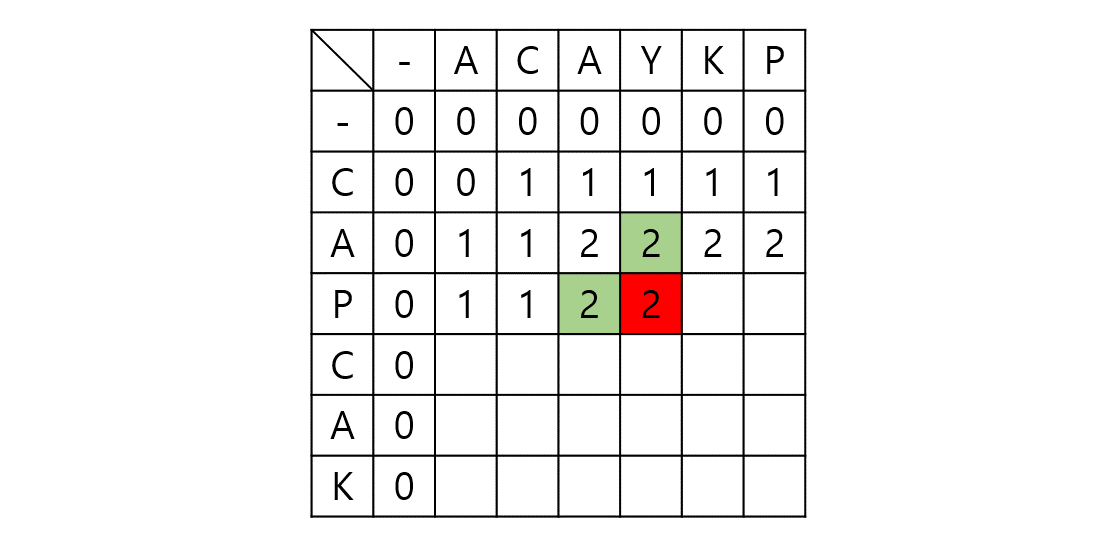
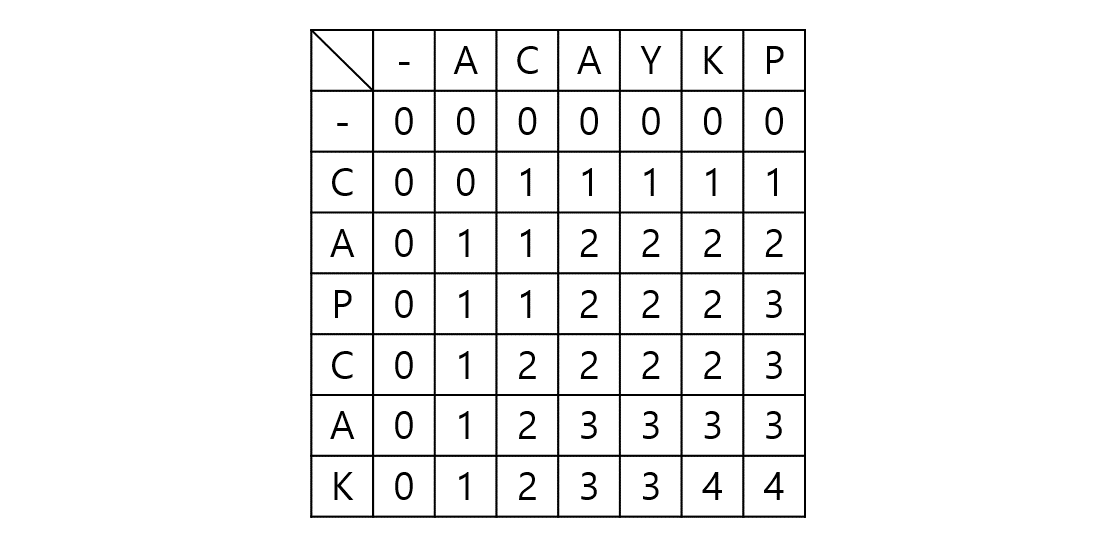
임의의 노드 s에서 임의의 노드 t까지 간다고 가정하자. 그렇다면 s와 t 사이의 노드 m에 대해 s - m까지의 최단거리와 m - t까지의 최단거리를 이용한다. (Optimal Substructure(Dynamic Programming), Edge Relaxation 과정이라고도 부른다.) dist[s][t]를 s에서 t로 가는 최단 거리라 하자. 만약 s, t가 서로 연결되어 있다면 그 간선의 가중치로, 그렇지 않다면 INF로 초기화될 것이다.
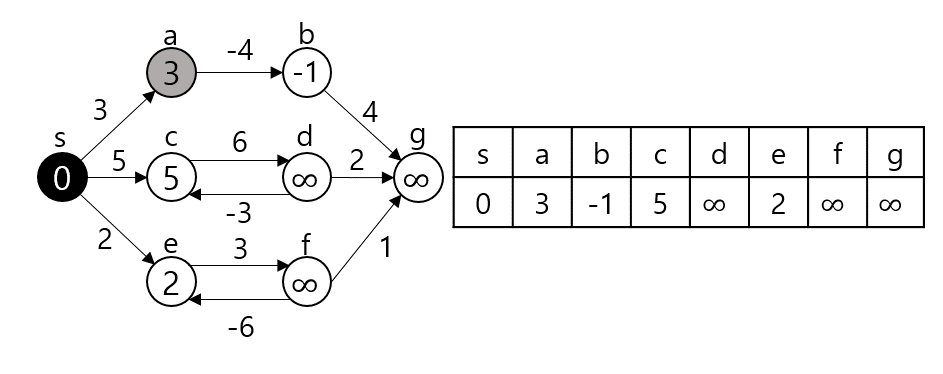
dist[s][t]를 구하는 과정은 s, t 사이의 모든 노드 m에 대해 dist[s][t]와 dist[s][m] + dist[m][t]값을 비교하여 갱신한다.
만약 $s - p_1-p_2-t$가 최단 경로라 할 때 $p_1$ 탐색 시점에서 dist[s][e]가 갱신되고 $p_2$ 탐색시점에서 또 갱신된다. 이런 식으로 모든 V에 대해 탐색을 진행하므로 시간복잡도는 $O(|V^3|)$이 된다.
음수 간선의 영향 및 음수 사이클 검출
벨만-포드 알고리즘(Bellman-Ford Algorithm)과 마찬가지로 그래프의 간선에 음수가 존재할 경우 그래프의 음수 사이클이 발생하지 않는다면 최단 거리가 성립함을 의미하므로 정상적으로 탐색이 가능하다. 벨만-포드 알고리즘은 $|V| - 1$번째 탐색 후 V번째 탐색 시 갱신되는 값이 있으면 음수 사이클이 있다고 결론을 내렸었다. 플로이드 워셜 알고리즘은 조금 다르다.
플로이드 워셜 알고리즘에서의 음수 사이클 검출은 자기 자신에게 가는 간선 거리를 검사하면 된다. 당연히 자기 자신을 경로로 갖는 Loop Edge가 존재하고 그게 음수 가중치를 갖지 않는 한 자기 자신의 경로는 항상 0이어야 한다. 그러나 음수 사이클이 존재한다면 음수 사이클에서 적당히 순회한 뒤 다시 자기자신을 재방문하면 음수가 되고 그게 최단 거리로 취급될 것이다.
따라서 임의의 i번째 노드에 대해 dist[i][i] < 0이면 해당 그래프는 음수 사이클을 갖고 있음을 알 수 있다.
python 코드
def floyd-warshall():
INF = float('inf')
V, E = map(int, input().split()) # 노드와 간선 개수 입력받는다 가정
dist = [[INF] * V for _ in range(V)] # 노드는 0부터 V - 1까지
for i in range(V):
dist[i][i] = 0
for _ in range(E):
s, d, w = map(int, input().split())
board[s][d] = w
for m in range(V):
for s in range(V):
for t in range(V):
dist[s][t] = min(dist[s][t], dist[s][m] + dist[m][t])
# 출발-도착점까지의 거리를 m을 경유했을 때와 비교
for i in range(V):
if dist[i][i] < 0:
# 자기자신의 경로길이가 음수면 음수 사이클 검출
return -1
return dist'Algorithms > Algorithm' 카테고리의 다른 글
| 크루스칼 알고리즘(Kruskal's Algorithm) (0) | 2021.08.02 |
|---|---|
| 프림 알고리즘(Prim's Algorithm) (0) | 2021.08.02 |
| 벨만-포드 알고리즘(Bellman-Ford Algorithm) (0) | 2021.08.01 |
| 다이나믹 프로그래밍(Dynamic Programming, 동적 계획법) (0) | 2021.07.23 |
| 순열, 조합 순서쌍 구현 (0) | 2021.07.22 |