읽기 전
- 불필요한 코드나 잘못 작성된 내용에 대한 지적은 언제나 환영합니다.
- 개인적으로 사용해보면서 배운 점을 정리한 글입니다.
크루스칼 알고리즘이란?
최소 신장 트리(Minimum Spanning Tree) 구현에 사용되는 알고리즘으로 가중치 그래프의 모든 간선들을 대상으로 "1) 최소 비용의 간선으로 구성, 2) 사이클을 형성하지 않음"의 조건을 지켜가며 각 단계마다 사이클을 이루지 않는 최소 비용 간선을 선택하여 최소 신장 트리를 완성하는 알고리즘이다. 프림 알고리즘과 마찬가지로 매 단계마다 최선의 해를 선택하기에 그리디 알고리즘에 바탕을 둔다.
크루스칼 알고리즘의 동작
- 그래프의 간선들을 가중치 기준으로 오름차순 정렬한다.
- 정렬된 간선들 중 순서대로 사이클을 형성하지 않는 간선들을 채택한다.
- 선택된 간선을 MST 집합에 넣는다.
- MST 집합의 원소 개수가 V - 1개가 될 때까지 2, 3을 반복한다.
사이클 생성 여부를 체크하는 알고리즘은 서로소 집합(Disjoint Set), 유니온 파인드(Union-Find)에 정리하였다.
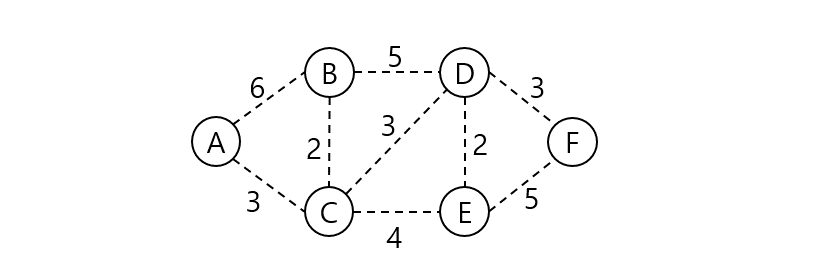
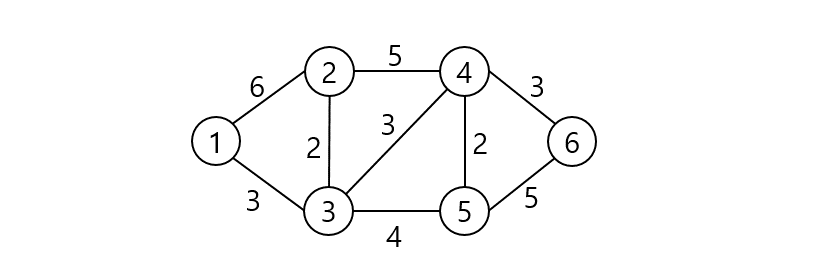
위 그래프의 최소 신장 트리를 크루스칼 알고리즘으로 구해보자.
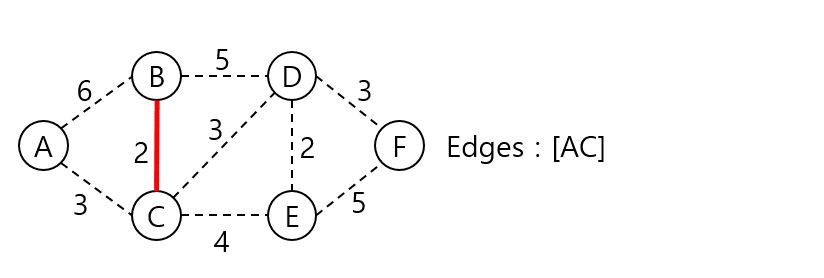
중복된 가중치가 있으나 연결 정점이 작은 순으로 시작하여 BC 간선에서 시작될 것이다.
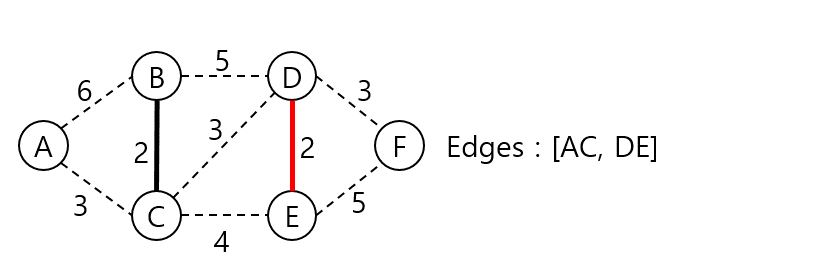
BC 간선 이후 DE 간선의 가중치가 가장 작으니 DE 간선을 MST 집합에 넣는다.
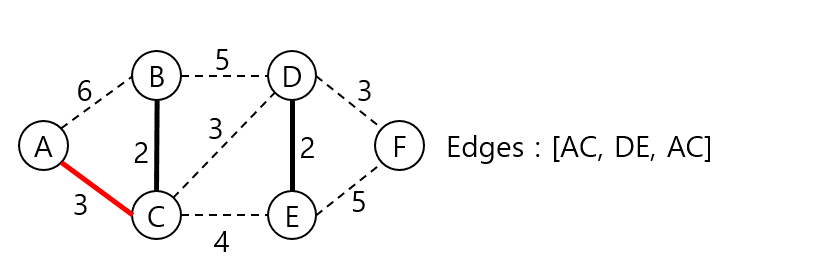
AC, CD, DF 간선의 가중치가 모두 동일하다. 순서대로 사이클을 형성하는지 체크한 결과 모두 사이클을 이루지는 않으니 AC 간선을 MST 집합에 넣는다.
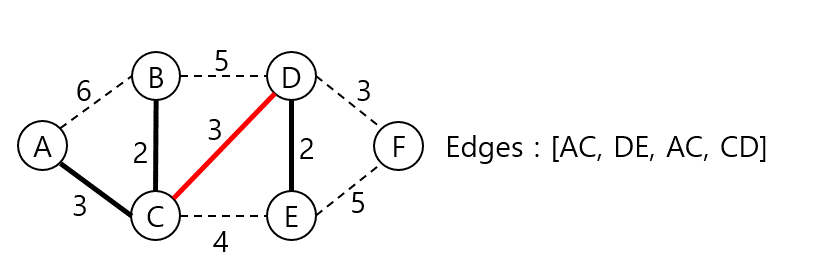
CD, DF의 간선의 가중치가 동일하다. 앞에서 사이클 여부를 체크한 결과 모두 형성하지 않았으므로 CD 간선을 MST 집합에 넣는다.
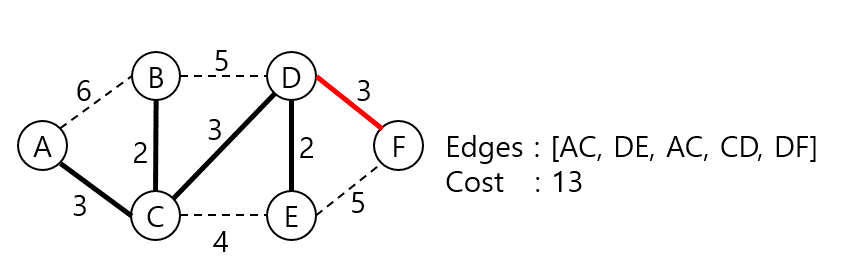
그 다음 가중칙 가장 작은 간선은 DF다. DF도 사이클을 형성하지 않으니 MST 집합에 넣어준다. MST 집합에 포함된 간선의 개수가 V - 1개가 되었으므로 탐색을 중단한다. 최소 신장 트리의 비용은 MST 집합에 속한 간선들의 가중치 합으로 13이 되겠다.
크루스칼 알고리즘의 구현
동작 과정을 보면 사이클을 찾는 과정에서 기존 서로소 집합(Disjoint Set), 유니온 파인드(Union-Find)는 클래스로 정의했지만 여기서는 함수로 구현해야겠다.
Python 코드
from collections import deque
def mst():
def upward(buf, idx):
parent = mst_nodes[idx]
if parent < 0:
return idx
buf.append(idx)
return upward(buf, parent)
def find(idx):
buf = []
result = upward(buf, idx)
for i in buf:
mst_nodes[i] = result
return result
def union(x, y):
x, y = find(x), find(y)
if x == y:
return False
if mst_nodes[x] < mst_nodes[y]:
mst_nodes[y] = x
elif mst_nodes[x] > mst_nodes[y]:
mst_nodes[x] = y
else:
mst_nodes[x] -= 1
mst_nodes[y] = x
return True
V, E = 6, 9
edges = [[1, 2, 6], [1, 3, 3], [2, 3, 2], [2, 4, 5],
[3, 4, 3], [3, 5, 4], [4, 5, 2], [4, 6, 3], [5, 6, 5]]
edges.sort(key=lambda x: x[2])
mst_graph = [[0] * V for _ in range(V)]
mst_nodes = [-1 for _ in range(V)]
mst = []
cost = 0
q = deque(edges)
while True:
u, v, w = q.popleft()
udx, vdx = u - 1, v - 1
if union(udx, vdx) is False:
continue
mst.append((u, v))
mst_graph[udx][vdx] = 1
mst_graph[vdx][udx] = 1
cost += w
if len(mst) == V - 1:
break
print(f'mst cost is {cost}')
print(mst)
for row in mst_graph:
print(*row)
mst()

크루스칼 알고리즘의 시간복잡도
union-find 알고리즘은 시간복잡도가 상수이므로 간선들을 가중치 기준으로 정렬하는 데 걸리는 시간에 의존한다. 일반적인 경우 빠른 정렬 알고리즘의 시간복잡도는 $O(nlog\ n)$이므로 이 경우 $O(Elog\ E)$가 된다. 우선순위 큐를 사용한 프림 알고리즘의 시간복잡도인 $O(Elog\ V + Vlog\ V)$과 비교했을 때 간선의 수가 적은 Sparse Graph의 경우 크루스칼 알고리즘이 유리하고 간선의 수가 많은 Dense Graph의 경우 프림 알고리즘이 유리하다.
- Sparse Graph는 크루스칼 알고리즘이 유리
- Dense Graph는 프림 알고리즘이 유리
관련 링크
최소 신장 트리(Minimum Spanning Tree)
프림 알고리즘(Prim's Algorithm
서로소 집합(Disjoint Set), 유니온 파인드(Union-Find)