읽기 전
- 불필요한 코드나 잘못 작성된 내용에 대한 지적은 언제나 환영합니다.
- 개인적으로 사용해보면서 배운 점을 정리한 글입니다.
문제 제기
변수 저장에 대해 물어보면 으레 지역/매개 변수는 스택, 기본 자료형은 선언된 위치에 의존, 참조 자료형은 reference만 선언된 위치에 의존하고 실제 객체는 힙에 저장된다고 말한다. 그런데 기본과 참조 자료형으로 나뉘는 변수에 대해서도 클래스, 인스턴스, 지역/매개 변수로 나뉘는데 이에 대해 구분해서 명확하게 알아둘 필요가 있어보여 정리하기로 했다.
주의점
변수(variable)가 (변수, 값)으로 구성되었다고 생각하면 혼동하기 쉽다. 엄연히 변수는 변수에 할당된 값을 가리키는 reference이고 변수에 할당된 값은 별개의 개념이라 생각하자.
public class Test {
static int classPrim = 10;
static String classRefer = new String("Variable");
static String classLiter = "Variable";
int instancePrim = 100;
String instanceRefer = new String("Variable");
String instanceLiter = "Variable";
public static void main(String[] args) {
Test test = new Test();
}
public void methodTest(int paramPrim, String paramRefer) {
int innerPrim = 10;
String innerRefer = new String("Variable");
String innerLiter = "Variable";
}
}지역/매개변수 위치
지역/매개변수 - 기본 자료형
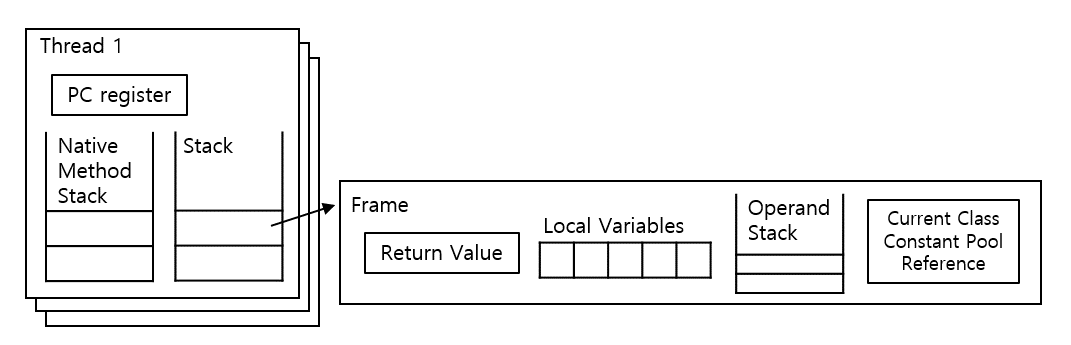
메소드 내에 생성되거나 전달된 지역/매개변수에 할당된 값이 기본자료형(정수, 소수, boolean)일 경우 stack에 저장된다고 보면 된다. 메소드가 종료되면 그대로 소멸한다.
지역/매개변수 - 참조 자료형
메소드 내에 생성되거나 전달된 변수에 참조 자료형(배열, 클래스 객체 등 new 연산자로 생성)이 할당될 경우 할당된 실제 객체는 heap에 저장되고 heap에 저장된 객체를 가르키는 reference가 stack에 저장된다. 역시나 메소드가 종료되면 객체에 생성되었던 데이터를 향한 heap 주소 reference가 삭제되고 연결이 끊긴 객체를 GC가 적당히 소멸시킨다.
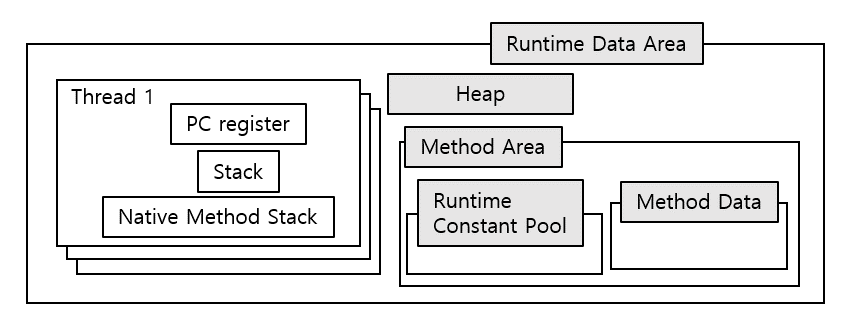
인스턴스 변수 위치 - 기본/참조 자료형
인스턴스 변수는 클래스를 기반으로 생성된 객체의 부분이므로 참조 자료형(객체) 내에 포함된 것으로 간주할 수 있다. 따라서 메소드 바깥에 선언된 static하지 않은 변수의 값들은 모두 생성된 객체를 따라 heap에 저장되고 인스턴스를 생성하고 호출하는 위치가 메소드 내부이므로 reference가 stack에 저장된다. 인스턴스 변수는 GC에 의해 객체가 소멸될 때까지 heap에 위치한다.
클래스 변수 위치
메소드 바깥에 선언되며 static한 변수를 클래스 변수라 한다. 클래스에 대한 객체를 생성하지 않고도 접근할 수 있는데 저장 위치에 대해 해외 포럼에서도 용어가 혼재되어 있다.
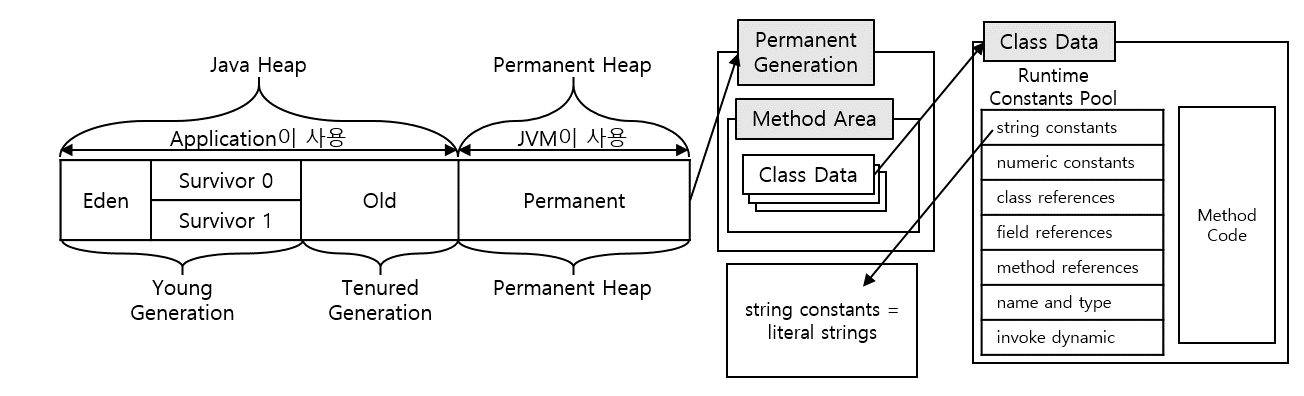
클래스 변수는 heap에서 "logical"하게 구분된 Permanent의 Method 영역에 저장된다. 정확히는 runtime constant pool에 존재한다. runtime constant pool에는 class meta data와 특이하게 numeric constant value, string constant value(interned strings)가 저장된다.
클래스 변수 - 기본 자료형
클래스 변수에 기본 자료형을 할당하면 runtime constant pool에 class meta data로 변수가 저장되고 변수에 할당된 값이 numeric constant value로 저장된다.
클래스 변수 - 참조 자료형
기본 자료형과 스트링을 제외한 참조 자료형(객체, 배열 등)인 경우 클래스 변수에 할당된 객체는 heap에 생성해두고 reference를 runtime constant pool에 저장한다.
String Literal
new 연산자로 생성하는 참조 자료형과는 달리 String은 Literal 형태로 변수에 값을 할당할 수 있다.(ex. String buf = "buf";) 그리고 이 값은 runtime constant pool의 string constant value에 저장되는데 참조 자료형임에도 heap에 생성하지 않았던 이유는 Java 초기 개발진은 String 객체는 자주 재사용될 여지가 있다 판단하여 heap과는 별개로 데이터를 저장하였다. 이러한 이유로 메소드 내에서든 객체 변수로든 클래스 변수로든 동일한 literal string이라면 동일한 주소를 가르키게 되었다. 이는 "==" 연산으로 확인할 수 있다.
요약
Java 7
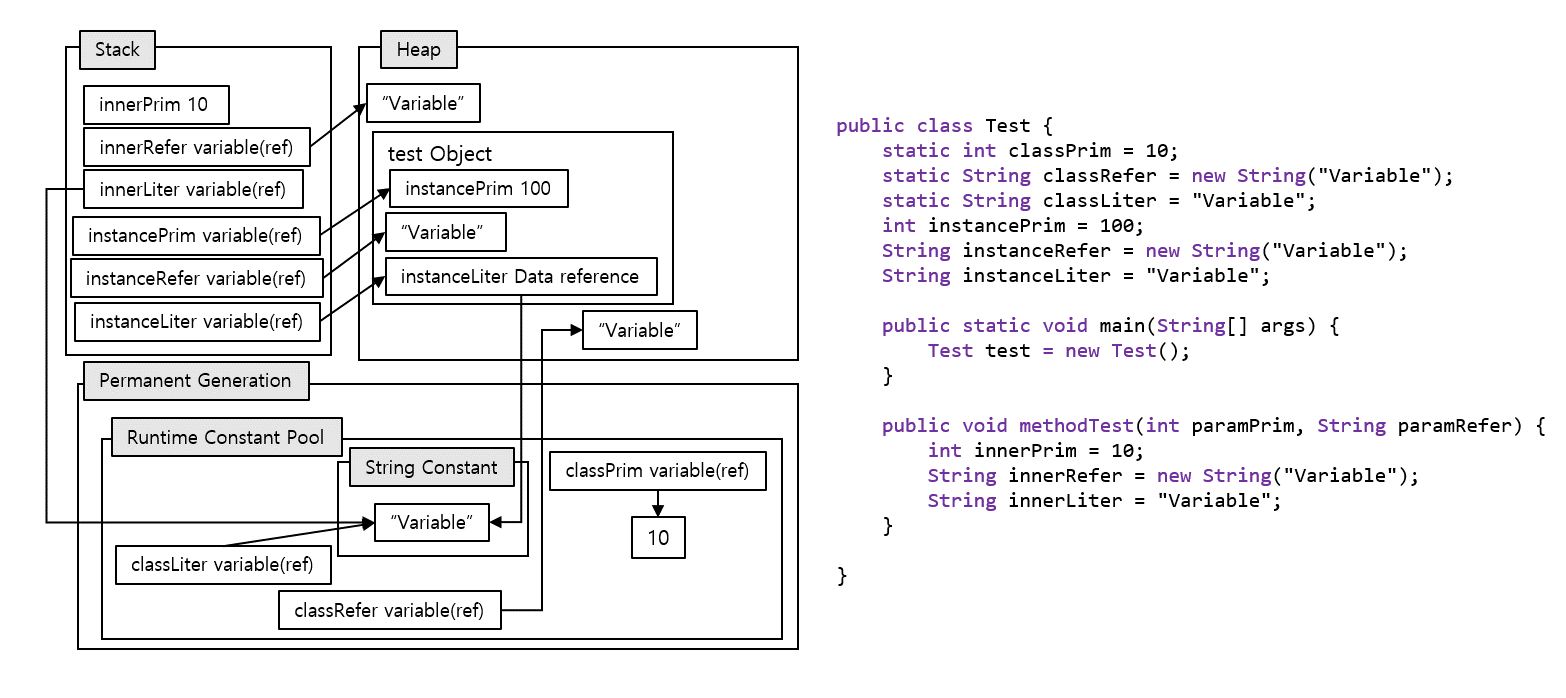
Permanent Generation이 존재했을 시기엔 변수의 위치와 할당된 값이 위 그림처럼 배치될 거라 이해했다.
Java 8
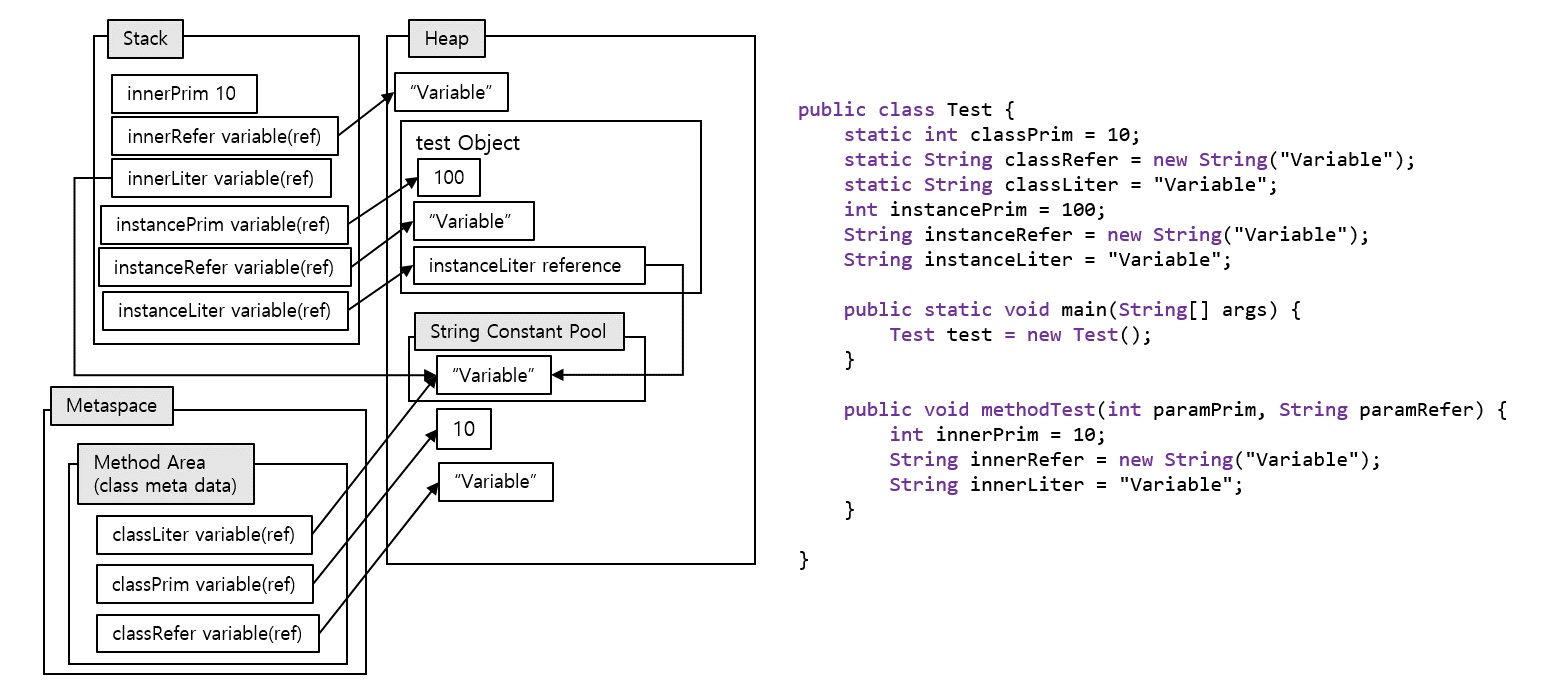
Java 8에서는 Permanent Generation이 삭제되고 Metaspace로 대체되면서 Metaspace는 class meta data만을 관리하고 클래스 변수의 리터럴 값을 저장하던 runtime constant pool의 numeric constants와 string constants가 heap 영역으로 이관되어 GC 대상에 적용되었다. 그 내용을 표현하면 위 그림처럼 배치될 것이다.
'Development > Java' 카테고리의 다른 글
| Java 명령어 실행 시 파일 확장자를 제거하는 이유 (0) | 2021.10.21 |
|---|---|
| Java float, double, BigDecimal - 부동소수점 오차 (2) | 2021.10.21 |
| Java 메소드를 클래스에 넣어야 하는 이유 - .class 파일 구조 (0) | 2021.10.21 |
| Java 런타임 데이터 영역 (8) | 2021.10.21 |
| Java 컴파일 및 런타임 환경 구조 (0) | 2021.10.21 |