읽기 전
- 불필요한 코드나 잘못 작성된 내용에 대한 지적은 언제나 환영합니다.
- 개인적으로 사용해보면서 배운 점을 정리한 글입니다.
문제 제기
Python을 사용한다면 반드시 성능 관련된 이슈가 나오고 그 중 자주 나오는 토픽으로 GIL을 꼽는다. 당장 알고리즘 문제 풀이에도 허용 시간이 C++/Java에 반해 길다는 점으로도 체감할 수 있다. 면접뿐만 아니라 개발에서도 GIL에 대한 이야기는 반드시 나온다는 생각에 시간을 내서 정리해보려 한다. 당장 컴파일 언어보다 느린 상황에 GIL까지 도입되었다니 그렇다면 왜 파이썬은 GIL을 채택했는가에 대해 알아보자.
GIL(Global Interpreter Lock)이란?
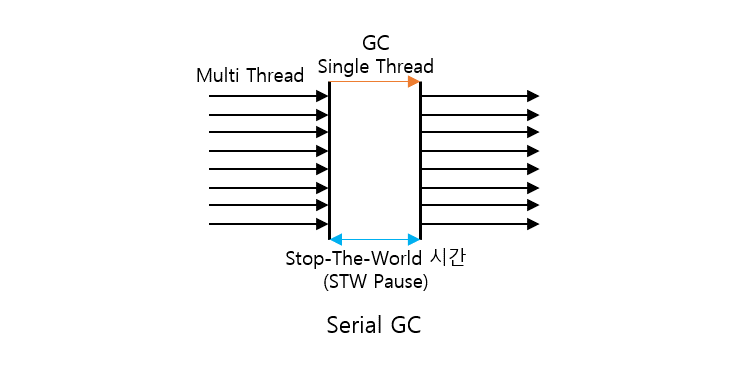
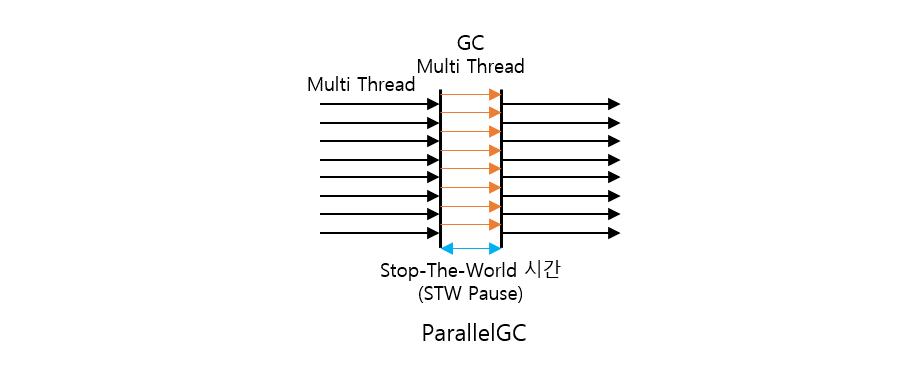
GIL은 파이썬 인터프리터에 한 개의 Thread가 하나의 바이트코드를 실행할 수 있도록 걸어두는 Lock이다. 하나의 Thread는 파이썬 인터프리터의 모든 자원을 사용하나 다른 Thread는 사용할 수 없도록 Lock을 건다는 의미이다. 그림으로 살펴보자.
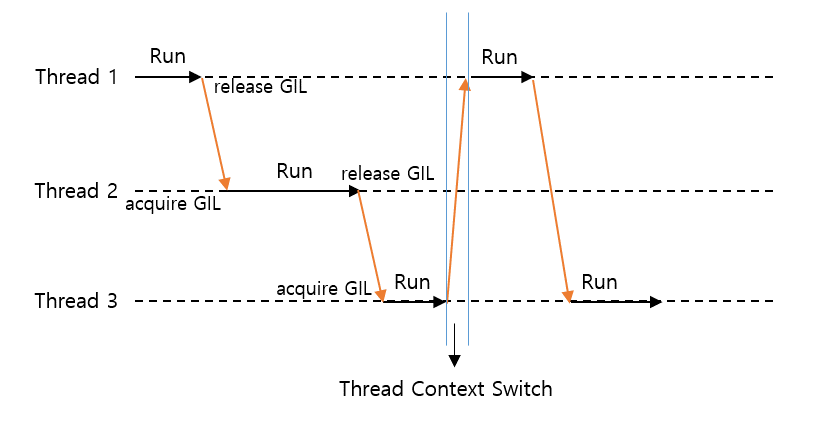
위 그림으로 인해 멀티 쓰레드로 구현했을 경우 GIL을 바꾸는 소위 Thread Context Switch 과정에 따른 비용이 발생하여 오히려 시간이 오래 걸리는 문제가 발생하기도 한다.
Python wiki의 GIL에 관한 설명 중 현재 포스팅과 관련없는 글을 제거하여 발췌한 내용이다.
In CPython, the global interpreter lock, or GIL, is a mutex that protects access to Python objects, preventing multiple threads from executing Python bytecodes at once. The GIL prevents race conditions and ensures thread safety. In short, this mutex is necessary mainly because CPython's memory management is not thread-safe.
In hindsight, the GIL is not ideal, since it prevents multithreaded CPython programs from taking full advantage of multiprocessor systems in certain situations. Luckily, many potentially blocking or long-running operations, such as I/O, image processing, and NumPy number crunching, happen outside the GIL. Therefore it is only in multithreaded programs that spend a lot of time inside the GIL, interpreting CPython bytecode, that the GIL becomes a bottleneck.
요약하자면 다음과 같다.
- GIL은 파이썬 객체로 접근함을 보호하기 위한 뮤텍스임
- CPython의 메모리 관리 정책은 Thread-Safe하지 않기 때문에 뮤텍스가 필요함
- 현재 멀티프로세서 환경에서는 GIL이 이상적이지 않음을 인정하나 I/O, 이미지 처리, NumPy 모듈의 number crunching 등 작업은 GIL 밖에서 이루어짐에 따라 오직 "멀티쓰레드"로 작성된 프로그램만이 바이트 코드를 인터프리팅 하느라 병목 현상이 발생해 성능이 저하될 것임
그렇다면 GIL이 도입된 배경으로는 CPython의 메모리 관리 정책이 왜 Thread-Safe하지 않은지 찾아보고 그 해결책이 GIL이어야만 했는지 알아보면 어느정도 궁금증이 해결될 듯하다.
Thread-Safe? Mutex?
자바에서도 그렇고 Thread-Safe에 대한 개념은 중요하다. 자바에서는 Synchronized 예약어로 구현되는데 사실상 mutex를 부여함과 다를 바 없다. 즉, 여러 쓰레드가 공유된 자원에 한 번에 접근하여 R/W 작업을 수행할 수 있는 상태를 Thread Safe하지 않다고 표현한다.
import threading
x = 0
def foo():
global x
for _ in range(1000000):
x += 1
def bar():
global x
for _ in range(1000000):
x += 1
thread1 = threading.Thread(target=foo)
thread2 = threading.Thread(target=bar)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print(x)x라는 공유된 변수에 thread1과 thread2가 동시에 접근해서 1씩 더하는 코드이다. 결과는 제각각이겠지만 2000000이 출력되어야 함에도 필자의 환경에서는 1310848이라는 전혀 엉뚱한 값이 출력된다. 이는 공유된 변수에 두 쓰레드가 동시에 접근하면서 발생된 문제다. x += 1은 x = x + 1이 축약된 문장으로 볼 수 있는데 우항의 x에 값을 대입하는 과정 중 다른 쓰레드가 값을 변경하면 이후 좌변의 x에 값을 대입할 땐 중간 결과가 무시된다.(소위 씹힌다.) 간단히 그림으로 표현하면 아래와 같다.

이렇듯 여러 쓰레드가 하나의 공유 자원이 동시에 접근하면서 발생하는 문제를 race condition(경쟁 상태)이라 하며 이 문제를 해결하기 위해 mutex 등을 도입한다.
Mutex는 이렇게 공유 자원에 하나의 쓰레드만 진입하며 작업을 처리할 수 있도록 만들어진 lock 개념이다. 간단히 비유하자면 한 사람만 이용할 수 있는 공중화장실은 출입문의 잠금장치를 열어야 이용이 가능하며 사람들은 줄 따위 서지 않고 호시탐탐 출입문을 노리고 있는 상황을 가정하자. 이용하고자 대기 중인 여러 사람이 Thread이고 화장실 시설이 resource, 화장실 출입문이 mutex, 화장실 출입문의 잠금장치가 lock이다.
CPython의 메모리 관리
Python wiki GIL 설명에서 CPython의 메모리 관리 전략은 Thread Safe하지 않다고 한다. CPython은 C언어로 구현된 파이썬 코어를 의미한다. C 언어는 Thread Safe를 위해 별도의 작업을 수행하지 않으며 race condition 대응은 사용자의 몫으로 남긴다. 그렇다면 C로 구현된 CPython 또한 동작 환경에선 race condition 대응을 위해 별도의 작업을 수행해야 함을 의미한다.
Reference counting
CPython은 C언어의 메모리 할당 관련 함수인 malloc()과 free()를 내부적으로 많이 사용할 것이다. 그러므로 자칫 메모리 누수의 위험이 존재한다. 이러한 이슈에 대응하기 위한 메모리 관리 전략으로 reference counting을 사용하고 있다. 간단히 설명하면 Python의 모든 객체에 카운트를 첨부하여 객체가 참조될 때 증가, 참조가 삭제되면 감소시키는 방식으로 동작한다. 객체에 대한 카운트가 0이 되면 메모리에서 할당이 삭제된다.(Python의 GC)
from sys import getrefcount
class foo():
def __init__(self):
print("Test Class")
a = foo()
print(f'a reference count {getrefcount(a)}')
b = a
print(f'a reference count {getrefcount(a)}')
c = a
print(f'a reference count {getrefcount(a)}')
b = 10
print(f'a reference count {getrefcount(a)}')
d = a
print(f'a reference count {getrefcount(a)}')
c = 0
print(f'a reference count {getrefcount(a)}')
'''
result :
a reference count 2
a reference count 3
a reference count 4
a reference count 3
a reference count 4
a reference count 3
'''foo() 클래스가 a에 할당되면서 참조값이 1 증가하고 getrefcount() 함수에 a 객체를 넣으면서 호출 시 1이 증가된 상태로 출력한다. 다른 변수에 a 객체를 할당하면 참조값이 증가하고 a 객체를 할당했던 변수에 다른 값을 넣어 참조를 끊으면 카운트가 감소함을 볼 수 있다. 이 값이 0이 되면 CPython이 알아서 메모리를 회수한다. 내부 코어 구조체와 코드를 찾아보자.
// Python 3.8 기준 내부 폴더 - Include/object.h 파일
typedef struct _object {
_PyObject_HEAD_EXTRA
Py_ssize_t ob_refcnt; // 참조값
struct _typeobject *ob_type;
} PyObject;객체를 나타내는 구조체에 ob_refcnt로 카운트 값을 갖게끔 하는 것을 볼 수 있다.
// Python 3.8 기준 내부 폴더 - Include/object.h 파일
static inline void _Py_DECREF(const char *filename, int lineno,
PyObject *op)
{
(void)filename;
(void)lineno;
_Py_DEC_REFTOTAL;
if (--op->ob_refcnt != 0) {
#ifdef Py_REF_DEBUG
if (op->ob_refcnt < 0) {
_Py_NegativeRefcount(filename, lineno, op);
}
#endif
}
else {
_Py_Dealloc(op);
}
}_Py_DECREF 함수에선 참조값이 0이면 객체를 메모리에서 해제함을 볼 수 있다.
Thread Safe를 위한 결정
앞서 C 언어에서는 race condition 해결을 사용자의 몫으로 남겨놨고 CPython은 메모리 관리 전략으로 Reference Counting을 도입하고 있음을 확인하였다. 그렇다면 Python은 Reference Counting을 Thread Safe하게 만들도록 별도의 작업을 수행해야 한다. 만약 Thread Safe하지 않다면 참조값을 증가시키는 행위를 수행이 참조값을 감소시키는 행위에 의해 무시되었을 때 엄연히 살아있는 객체를 죽여버리거나 그 반대의 경우 메모리 누수가 발생하여 파멸적인 결과를 낳을 수 있기 때문이다.
CPython의 메모리 관리를 Thread Safe하게 만들기 위해 뮤텍스를 도입할 수 있으며 객체 각각에 대한 뮤텍스를 생성하여 관리하면 되겠다. 그러나 객체 각각에 대해 하나씩 대응되면 뮤텍스로 보호하면 성능 상의 이슈뿐만 아니라 데드락이라는 치명적인 상황을 초래할 수 있다.
결국 Python은 뮤텍스로 모든 reference에 대해 보호하지 않고 파이썬 인터프리터 자체를 하나의 쓰레드만 사용할 수 있도록 global하게 잠궈버리면 해결이 가능함을 이유로 쓰레드가 Python bytecode를 실행하기 위해서는 파이썬 인터프리터를 잠군 Interpreter Lock을 획득하여 작업을 해야하는 정책을 채택하였다. 이를 Global Interpreter Lock이라 부른다.
GIL 선정 이유
Python은 1991년에 도입되었는데 Multi Thread의 개념은 상당히 오래되었으나 당장 인텔 펜티엄 4가 2002년에 SMT(Simultaneous MultiThreading, SMT)를 처음으로 지원했다는 점을 고려하면 이 시기에는 Multi Thread에 대해 고민이 주류가 아니었을 것이다. 5년 후에 배포된 Java는 Multi Thread를 고려하였다는 점으로 볼 때 아키텍처가 급격하게 발전한 탓도 있으리라 생각한다. Python 도입 이후 많은 C extension들이 이미 만들어졌는데, Multi Thread 개념이 정착되고 thread로 인한 문제를 해결하기 위해서 Python 진영에서 만들어낸 C extension들을 새로운 메모리 관리 방법에 맞춰서 모두 바꾸는 것은 불가능했다. 대신 Python이 GIL을 도입하면 C extension들을 바꾸지 않아도 현실적으로 해결이 가능했기에 도입된 것이다.
Python은 싱글 쓰레드로만 동작해야 하나?
이 부분에 대해서는 개발자들의 역량에 따라 달라진다. Python은 threading 모듈, multiprocessing 모듈 등 몇 가지 옵션을 제공한다. 하나의 포스팅으로 정리하기에는 양이 좀 많을 것으로 예상되기에 이번 포스팅에서는 자세히 다루지는 않겠지만 간단히 적어본다.
I/O bound
Python의 GIL은 파이썬 인터프리터를 Global하게 잠궈서 bytecode를 하나의 쓰레드만 처리할 수 있도록 하는 정책이다. 그러면 bytecode처리는 하드웨어 관점에서 CPU가 담당하게 되고 CPU-bound 작업이 아니라 I/O 바운드 작업이라면 요청을 걸어두고 대기하면 되기 때문에 멀티 쓰레드로 구현했을 때 성능을 개선시킬 수 있다.
Multi Processing
병렬 처리를 위해 쓰레드가 아니라 멀티 프로세싱 모듈을 사용할 수도 있다. 하나의 인터프리터가 아니라 여러 프로세스를 구동시켜서 작업을 처리함을 의미한다. 즉, 적절히 작업을 분할하여 각 프로세스에 배분해야 하며 쓰레드 간 정보 전달보다 프로세스간 정보 전달(IPC)의 코스트가 높기 때문에 오히려 기본적으로 제공되는 단일 쓰레드에서의 성능이 더 좋을 수 있다. 따라서, 적절히 상황을 보면서 도입해야 한다.
결론
결론적으로 GIL은 멀티 쓰레드에 대한 개념이 범용적으로 쓰이지 않던 시절에 개발된 언어의 한계를 해결하기 위해 도입된 개념으로 "안전"을 얻고 "성능"을 잃는 trade-off 정책으로 볼 수 있다. 따라서, 하드웨어를 직접 컨트롤하거나 압도적 퍼포먼스를 보여야 하는 프로그램에 Python을 도입하려면 어느정도 각오를 가지고 프로그램을 설계해야 함을 의미한다. CPU 자원 처리 권한을 lock하는 개념이기 때문에 I/O 기기에 요청만 하고 결과를 받아보는 I/O bound 작업은 별도로 분리하여 멀티 쓰레드로 처리하면 성능 개선을 도모할 수 있으나 거대한 프로젝트에서 작업을 분리하여 처리하는 중 발생할 수 있는 side-effect를 고려할 실력이 아니라면 얌전히 싱글 쓰레드 환경에서 로직을 다듬는 게 좋아보이긴 한다.
'Development > Python' 카테고리의 다른 글
| Python 함수 코드가 일반 코드보다 빠른 이유 (1) | 2021.08.01 |
|---|