읽기 전
- 불필요한 코드나 잘못 작성된 내용에 대한 지적은 언제나 환영합니다.
- 개인적으로 사용해보면서 배운 점을 정리한 글입니다.
- 기술면접만을 준비하기보다 비전공자 입장에서 OS의 기본적인 내용을 짚기 위해 작성되었습니다.
중요도 - 중: 메모리/가상메모리의 페이징과 요구페이징 전반은 물어볼 법하다.
메모리 관리
주소 바인딩
프로세스의 논리적 주소(프로세스의 주소공간)을 물리적 주소로 연결시키는 작업
- 컴파일 타임 바인딩 : 프로그램을 컴파일할 때 결정되는 주소 바인딩 방식
- 물리적 메모리의 절대 주소로 적재되므로 절대 코드 생성 바인딩 방식이라고도 함
- 메모리 주소를 변경하려면 재컴파일해야 함
- 로드 타임 바인딩 : 프로그램이 시작될 때 물리적 주소가 결정됨
- 프로그램에 물리적 메모리 주소 부여를 로더가 책임, 프로그램 종료될 때까지 주소 고정
- 실행시간 바인딩 : 프로그램 실행 후에도 물리적 주소가 변경될 수 있음
- CPU의 주소 참조 때마다 해당 데이터가 물리적 메모리의 어느 위치에 있는 지 주소 매핑 테이블로 바인딩 체크해야 함
- 기준 레지스터, 한계 레지스터로 주소 범위를 체크하고 MMU라는 하드웨어 장치 필요
- MMU기법 : 한계 레지스터로 CPU가 가진 논리적 주소 범위를 체크하고 CPU가 프로세스의 논리적 주소를 가질 때 MMU가 프로세스의 기준 레지스터를 더해 실제 물리적 주소 시작점을 가리킴.
메모리 관리 용어
- 동적 로딩 : 프로세스의 일부만 메모리에 적재하고 실행이 필요할 때만 추가로 적재
- linking : 프로그래머의 소스코드를 컴파일한 결과인 목적파일, 컴파일된 라이브러리 파일을 묶어 실행파일로 만드는 과정
- 정적 linking : 프로그래머의 코드와 라이브러리의 코드가 합쳐져서 실행 파일 생성
- 동적 linking : 라이브러리는 제외하며 호출이 되어서야 라이브러리 연결 수행
- 스텁(stub) : 호출한 라이브러리가 메모리에 존재하는 지 체크. 없으면 디스크에서 동적 라이브러리를 찾아 메모리에 적재함
- 중첩 : 프로세스의 주소 공간을 분할해 실제 필요한 부분만 적재. 동적 로딩과 유사하나 초창기 메모리 자원이 단일 프로세스조차 적재하기 힘들 때 도입되던 개념
- 스와핑 : 중기 스케쥴러에 의해 메모리에서 디스크로 내리거나 그 반대의 과정
- 컴파일 타임, 로드 타임 바인딩은 물리 주소가 고정되므로 swap-in 시 기존 주소에 적재
- 스와핑 시간은 디스크 탐색/회전지연 시간보다 실제 데이터 R/W 작업 시간이 주요함
- 프로세스의 주소 공간이 순차적으로 적재되므로 탐색시간은 적다.
물리적 메모리 할당 방식
- 운영체제 상주 영역 : 인터럽트 벡터, 운영체제 커널 등이 적재된 낮은 주소 영역
- 사용자 프로세스 영역 : 나머지 높은 주소 영역
- 연속할당 방식 : 프로세스를 메모리의 연속된 공간에 적재
- 고정 분할 : 물리적 메모리를 고정 크기로 사전에 분할하는 방식이다. 각 분할에는 1개의 프로그램만 적재 가능하며 수행 가능한 프로그램 크기에 제약이 발생한다.
- 외부 조각 : 분할의 크기 < 프로그램 크기로 적재가 불가능해 낭비되는 영역
- 내부 조각 : 분할의 크기 > 프로그램 크기로 남는 메모리임에도 사용되지 않는 영역
- 가변 분할 : 적재되는 프로그램에 따라 분할의 크기/개수가 동적으로 변화
- 프로그램보다 큰 분할은 생성하지 않아 내부 조각(단편화, fragment) 없음
- 기존 할당된 분할보다 작은 프로그램이 적재되면 나머지 공간에 외부 조각 발생
- 컴팩션 : 사용 중인 공간을 한쪽으로 몰아 큰 가용 공간 생성. 비용이 많이 들고 물리적 주소 이동이 가능한 실행 시간 바인딩 방식이 지원되어야 함.(외부조각 해결)
- 동적 메모리 할당 문제 : n크기의 프로세스를 적재할 때 어떤 기준으로 할 지 결정
- 최초적합 : 가장 먼저 발견되는 가능 공간에 적재. 시간 효율 증가
- 최적적합 : 가장 n에 가까운 가능 공간에 적재. 공간 효율 증가
- 고정 분할 : 물리적 메모리를 고정 크기로 사전에 분할하는 방식이다. 각 분할에는 1개의 프로그램만 적재 가능하며 수행 가능한 프로그램 크기에 제약이 발생한다.
- 불연속할당 방식 : 하나의 프로세스를 여러 위치에 분산시켜 할당
- 페이징 기법 : 동일 크기로 나누어 올림
- 세그멘테이션 기법 : 의미 단위로 나누어 올림. 크기는 일정하지 않다.
- 페이지드 세그멘테이션 기법 : 의미 단위로 분할하되 그걸 다시 동일 크기로 분할
페이징 기법
- 프레임 : 물리적 메모리를 페이징과 동일 크기로 분할한 단위.
- 동적 메모리 할당 문제 해결되었으나 마지막 조각은 내부조각 발생 가능
- 페이지 테이블 : 한 프로세스의 여러 페이지가 물리적 메모리에 혼재되어 있으므로 페이지 별 논리주소를 물리 주소로의 변환을 위한 표
- 페이징의 주소 변환 : CPU의 논리적 주소를 페이지 번호(p), 페이지 오프셋(d)로 나눠서 활용
- 페이지 번호 : 페이지 테이블의 인덱스, 물리적 메모리 시작 위치를 알 수 있다.
- 페이지 오프셋 : 페이지 내 변위. 페이지 번호로 찾은 기준 주소 값에 더하면 요청한 논리 주소에 매칭되는 물리 주소를 얻음
- 페이지 테이블 접근 오버헤드 : 페이지 테이블 접근 + 반환된 주소로의 접근 오버헤드
- TLB : 페이지 테이블 접근 오버헤드를 줄이기 위해 도입된 고속 하드웨어 캐시
- 가격이 비싸 용량이 작음. 빈번히 참조되는 페이지에 대한 정보만 갖음
- 요청 페이지 번호가 없으면 페이지 테이블 조회. 있으면 메모리의 프레임으로 직행
- 문맥 교환 시 TLB 내용도 리셋된다.
- TLB와 페이지 테이블의 차이점 : 페이지 테이블은 배열과 구조가 유사. TLB는 속도 향상을 위해 연관 레지스터 사용으로 병렬 탐색을 지원하여 동시에 전체 탐색이 가능
- TLB의 평균 메모리 접근 시간(Effective Access Time:EAT) : 메모리 접근 시간 1, 레지스터 탐색 ε, TLB 존재 확률 α라고 하면 EAT = (1+ϵ)α+(2+ϵ)(1−α)=2+ϵ−α
- 1+ϵ은 레지스터 접근 시간과 실제 메모리 접근을 더한 값, 2+ϵ은 TLB에 없어 페이지 테이블에 접근한 시간도 더해진 값이다. ε이 유의미하게 작기 때문에 성능개선이 된다.
- TLB : 페이지 테이블 접근 오버헤드를 줄이기 위해 도입된 고속 하드웨어 캐시
- 계층적 페이징 : 프로세스가 요구하는 메모리의 크기가 커짐에 따라 페이지의 수가 많아지고 그에 따른 페이지 테이블의 크기도 과도하게 커진다. 그러나 대부분의 프로그램은 그런 경우가 없어 요구메모리가 큰 프로세스 대응에 공간 낭비 발생을 막기 위해 도입
- 장점 : 사용되지 않는 공간을 NULL로 표시하여 페이지 테이블에 사용되는 공간 절약
- 단점 : 주소 변환을 위해 접근하는 페이지 테이블 수 증가로 시간 손해
- 외부 페이지 테이블 : 논리 주소로부터 다음 페이지 테이블의 주소와 매칭
- 내부 페이지 테이블 : 마지막 페이지 테이블. 실제 메모리 프레임 주소와 매칭
- 계층적 페이징의 시간 해결 : TLB를 통해 해결. 4단계 페이징을 예를 들어보자.EAT = (100+20)⋅0.9 + (500+20)⋅0.1 = 160(ns)으로 시간 부담이 확연히 줄어듬
- ex) 페이지 테이블 접근 시간 100ns, TLB 접근 시간 20ns, TLB 매칭 확률 90%라 하자.
- 역페이지 테이블 : 물리 메모리의 페이지 프레임 하나씩 항목을 둬서 관리. pid와 페이지 번호가 일치하는 항목의 번호가 실제 프레임의 위치가 됨. 시간 효율 개선을 위해 반드시 연관 레지스터를 사용해야 함.
- 공유 페이지 : 메모리 공간 효율 제고를 위해 프로세스들이 공통으로 공유하는 페이지 운용
- 공유 코드 : 재진입 가능 코드, 순수 코드라고도 불리며 여러 프로세스에 의해 공통으로 사용되도록 작성된 코드
- 반드시 읽기 전용이어야 한다.
- 모든 프로세스의 논리적 공간에서 공유코드는 동일한 위치를 가져야 한다.
- 사유 페이지/데이터 : 공유 페이지를 제외한 프로세스가 독자적으로 사용하는 공간
- 공유 코드 : 재진입 가능 코드, 순수 코드라고도 불리며 여러 프로세스에 의해 공통으로 사용되도록 작성된 코드
- 페이지 테이블의 메모리 보호 : 주소 변환 정보뿐만 아니라 보호비트/유효-무효 비트를 가짐
- 보호비트 : 각 페이지에 대해 R-W/RO 등의 권한 설정에 사용
- 유효-무효비트(valid-invalid bit) : 유효라면 해당 메모리 프레임에 페이지 존재, 무효라면 프로세스가 해당 주소를 사용하지 않거나 메모리가 아닌 백킹스토어(스왑영역)에 존재해 해당 프레임에 유효한 접근 권한이 없음을 명시
세그멘테이션
- 세그먼트 테이블 : 주소 변환을 위한 테이블
- 기준점/한계점 : 물리적 메모리에서의 세그먼트 시작 위치/세그먼트의 길이
- 기준 레지스터/길이 레지스터 : 세그먼트 테이블의 물리적 시작 위치/세그먼트의 개수
- 세그멘테이션의 주소 변환 : CPU의 논리적 주소를 세그먼트 번호/오프셋으로 나눠 관리
- 세그먼트 번호 : 프로제스 주소 공간에서 몇 번째 세그먼트에 속하는지 표시
- 오프셋 : 세그먼트 번호에 해당하는 세그먼트 내의 변위 값
- 세그먼트 번호 > 길이 레지스터 : 존재하지 않는 세그먼트에 대한 접근으로 예외 상황
- 오프셋 > 한계점 : 세그먼트 범위 초과로 예외 상황
- 보호비트/유효비트 : 페이징 기법과 동일하나 적용대상이 세그먼트임
- 공유 세그먼트 : 의미 단위로 나뉘어 공유, 보안 측면에서 페이징보다 효과적
- 사유 데이터가 한 영역에 존재하지 않음(페이징은 한 영역에 존재 가능)
- 크기가 일정하지 않아 가변 분할에서의 문제점을 동일하게 갖음
페이지드 세그멘테이션(Paged Segmentation)
프로그램을 의미 단위인 세그먼트로 분할하되 세그먼트는 동일 크기의 페이지로 재분할
- 세그먼트의 크기는 페이지 크기의 배수
- 페이지트 세그멘테이션 주소 변환 : CPU의 논리적 주소를 세그먼트 번호/오프셋으로 관리
- (외부)세그먼트 테이블 : 세그먼트 길이와 해당 세그먼트의 페이지 테이블 시작 주소를 가짐
- (내부)페이지 테이블 : 각 세그먼트가 갖는 테이블. 물리적 메모리 프레임 위치, 변위값 가짐
- 논리 주소의 상위 비트인 세그먼트 번호로 세그먼트 테이블 접근, 해당 항목이 갖고 있는 세그먼트 길이와 오프셋 비교(오프셋 > 길이 : 세그먼트 범위 초과)
- 1이 유효하면 오프셋을 페이지 번호와 페이지 오프셋으로 쪼개 페이지 테이블 접근
- 페이지 테이블에서 물리적 메모리 프레임 위치와 프레임 내 변위값 찾아 접근
가상 메모리 관리
프로그램이 물리적 메모리를 고려하지 않고 0부터 시작하는 자신만의 메모리를 가정한 공간
- 일부는 물리적 메모리에 일부는 디스크의 스와핑 영역에 존재
- 프로세스의 주소 공간을 메모리로 적재하는 기법 : 단위에 따라 요구 페이징/ 세그멘테이션
요구 페이징
당장 사용할 페이지만을 올려두고 CPU의 요청에 따라 보조기억 장치의 swap 영역에서 로드해 메모리에 적재한다.
- 물리적 메모리 용량 제약을 벗어나게 하는 효과
- 모든 프로그램은 자신만의 가상 메모리 주소를 갖고 OS는 이 가상 메모리 주소를 물리적 주소로 매핑하는 기술을 사용해 주소를 변환 후 물리적 메모리에 프로그램을 적재
- 프로그램의 크기가 크더라도 모든 요소가 동시에 사용되진 않는다는 점을 참고하여 현재 사용 중인 크기만 적재하고 나머지는 보조기억 장치에 저장했다가 필요할 때 적재
- 페이징 테이블에 유효-무효 비트를 둬서 메모리 적재 여부 체크
- 프로세스 시작 전에는 모든 페이지의 유효-무효 비트값은 무효. 적재 시 valid로 변경
- swap out될 valid에서 invalid로 변경
- 페이지 부재(fault) : 페이지가 메모리에 없어 무효로 마킹된 상태
- 요구 페이징의 page fault 처리
- 주소 변환을 담당하는 MMU가 page fault trap 발생
- CPU의 제어권이 커널 모드로 이양, page fault 처리루틴 수행. 적법하면 물리적 메모리에 빈 프레임을 할당 받아 해당 페이지를 load
- 빈 프레임이 없으면 적재된 페이지 중 하나를 swap-out
- swap-in은 소요시간이 길어 페이지 부재 발생 프로세스 봉쇄로 전환 - PCB에 저장
- swap-in 완료 시 인터럽트 발생, 유효비트 valid 마킹, 프로세스 준비 큐로 이동
- 해당 페이지의 접근의 적법 여부 체크. 위반 시 프로세스 종료
- 요구 페이징의 성능 : page fault 발생 빈도가 가장 큰 영향(swap-in 때문)
- 유효 접근시간 : 요청한 페이지를 참조하는 데 걸리는 시간. (P = page fault rate)
- (1−P) * 메모리 접근 시간
- P * 페이지 부재 발생 처리 오버헤드
- P * 빈 프레임이 없을 경우 swap-out 오버헤드 + 요청 페이지의 swap-in 오버헤드
- P * 프로세스의 재시작 오버헤드
유효 접근시간의 계산은 위 4개의 값을 더한 결과다.
- 유효 접근시간 : 요청한 페이지를 참조하는 데 걸리는 시간. (P = page fault rate)
페이지 교체
- 전역 교체 : 교체 알고리즘의 대상이 모든 페이지 프레임인 경우
- 지역 교체 :교체 알고리즘을 프로세스 별로 독자적으로 적용
- 교체 알고리즘 : swap-out할 시 어떤 프로세스에 수행할 지 결정하는 알고리즘
- page falut rate 최소화가 목적
- 페이지 참고열에 대해 page fault rate를 계산하여 성능 평가
- 최적 페이지 교체 - MIN, OPT
- 가장 최적의 알고리즘, 미래의 페이지 참조를 알고 있어 실제 적용은 안됨
- 성능 평가의 상한선
- 가장 먼 미래에 참조될 페이지를 swap-out하면 된다.
- FIFO(First In Fist Out)
- 향후 참고 가능성 고려 없이 물리적 메모리에 들어온 순서대로 swap-out
- 단점 : 먼저 진입한 페이지의 참조가 계속 빈번하면 page fault도 빈번히 발생
- FIFO 이상현상(anomaly) : 메모리를 증가시켰음에도 page fault가 증가
- LRU(Least Recently Used)
- 시간 지역성(temporal locality) : 최근 참조된 페이지는 다시 참조될 가능성이 높다.
- 마지막 참조 시점이 가장 오래된 페이지는 swap-out
- LFU(Least Frequently Used)
- 물리적 메모리에 적재된 페이지들 중 과거 참조 횟수가 가장 적은 페이지 swap-out
- 여러 개라면 그들 중 더 오래된 페이지 swap-out이 바람직
- Incache-LFU : 메모리에 적재된 순간부터 count, swap-in되면 1부터 다시 count
- Perfect-LFU : 메모리 적재 여부와 상관없이 count, 오버헤드가 크다.
- 장점 : LRU보다 장기적인 기록 반영 가능
- 단점 : 시간에 따른 참조변화 반영 불가능. LRU보다 구현이 어려움. 특정 페이지를 집중적으로 사용하다 계속 적재될 경우 불필요하게 상주할 수 있음
- 물리적 메모리에 적재된 페이지들 중 과거 참조 횟수가 가장 적은 페이지 swap-out
- 클럭
- LRU/LFU가 참조시각, 횟수를 소프트웨어적으로 유지,비교를 요구하여 오버헤드 발생
- 하드웨어 장치를 둬서 오버헤드 감소, 대부분의 시스템에서 도입
- LRU 근사 알고리즘으로 NUR(Not Used Recently), NRU(Not Recently Used)로도 부름
- 오랫동안 참조되지 않은 페이지 중 하나를 교체, LRU와 달리 교체된 페이지가 가장 오래 전에 참조된 페이지임을 보장하지 않음
- 페이지 프레임의 참조 비트를 조사
- 프레임의 페이지 참고 시 참조 비트를 1로 마킹
- 클럭 포인터가 지나갈 때 1로 마킹된 항목은 0으로, 이미 0인 경우는 swap-out
- 최초 참조 이후 1번의 기회를 준다는 의미로 2차 기회 알고리즘으로도 부름
페이지 프레임의 할당
- 할당 알고리즘 : 프로세스가 여러 개 수행될 때 각 프로세스의 메모리 할당 크기를 결정한다.
- 균등 할당 : 모든 프로세스 동일 프레임 할당
- 비례 할당 : 프로세스 크기에 맞춰 할당
- 우선순위 할당 : 당장 CPU에 실행될 프로세스와 그렇지 않은 프로세스 구분하여 할당
스레싱(thrashing)
집중적으로 사용되는 페이지들을 한번에 적재하지 못해 page fault rate가 크게 상승하여 CPU 이용률이 급격하게 감소하는 현상
- MPD(Multi-Processing Degree, 다중 프로그래밍 정도) : 메모리에 동시에 적재되어 있는 프로세스의 수
- OS는 CPU 이용률이 낮으면 MPD가 적다고 해석
- 준비 큐가 비어있는 경우 MPD가 적어 이들이 모두 I/O 작업 중이라 판단하여 MPD를 증가시키려고 함
- MPD 과도하게 증가 시 프로세스 할당 메모리가 급격히 감소하여 페이지 부재 빈번히 발생
- 빈번한 페이지 부재 처리로 swap-in 계속 발생하여 CPU 이용률 감소
- 1-2를 순환하며 악순환 발생 - 대부분의 시간에 CPU가 일을 안함
- 스레싱 방지 알고리즘 : MPD를 적절히 조절하는 알고리즘
- 워킹셋 알고리즘 : 지역성 집합이 메모리에 동시에 적재되도록 보장
- 지역성 집합 : 일정 시간 집중적으로 참조되는 페이지 집합
- 워킹셋 : 한 번에 메모리에 적재되어야 하는 페이지들의 집합
- 워킹셋을 구상하는 페이지들이 한번에 적재가능한 경우에만 메모리 할당
- 적재가 불가능하면 전체 반환 후 swap-out
- 워킹셋 윈도우 : 워킹셋 생성을 위해 사용하는 윈도우. 너무 크면 지역성 집합은 많이 수용하나 MPD 감소, 너무 작으면 지역성 집합을 모두 수용하지 못함
아래 그림은 워킹셋 알고리즘의 작동 도식이다. 워킹셋 윈도우에 포함되는 페이지 참조 빈도에 따라 워킹셋 집합의 크기도 조절되어 동적으로 프레임 할당 기능까지 수행
- 워킹셋 알고리즘 : 지역성 집합이 메모리에 동시에 적재되도록 보장
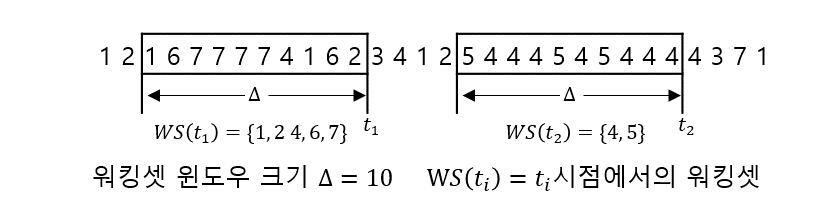
- 페이지 부재 빈도(Page Fault Frequency: PFF) 알고리즘 : 프로세스의 부재율을 주기적으로 조사한 뒤 각 프로세스에 할당할 메모리 양 동적으로 조절
- 프로세스 페이지 부재율 > 상한값 : 프로세스에 할당된 프레임 부족 간주, 빈 프레임 없으면 swap-out하여 MPD 감소
- 프로세스 페이지 부재율 < 하한값 : 프로세스에 필요 이상의 프레임 할당 간주, 할당된 프레임 감소
- 위 방식대로 할당했음에도 프레임이 남으면 swap-in하여 MPD 증가
웹캐싱 기법
컨텐츠 전송 네트워크(Contents Delivery Network: CDN) 서비스 활성화로 원격지의 객체를 캐싱하여 사용자가 인터넷 정보에 신속한 접근이 가능하게 함을 목적으로 한다. 웹 사용자에 의해 빈번히 요청되는 데이터를 웹캐시 서버에 보관해 빠른 서비스를 가능하게 하는 기법
- 프락시 서버 : 웹 사용자의 서비스 지연시간 감소를 목적으로 도입, 네트워크 대역폭 절약과 웹서버 부하 감소 역할
- 역방향 프락시 캐시 : 웹서버에 도입되는 개념으로 특정 그룹의 웹서버 객체들을 캐싱하여 서버 부하를 직접적으로 줄이고 사용자의 지연시간도 감소시킴
- 캐시 교체 알고리즘 : 한정된 캐시 공간으로 인해 어떤 객체를 캐시에 보관/삭제할 지 온라인으로 결정
- 일관성 유지 : 근원지 서버의 웹 객체가 변경될 수 있어 캐싱된 객체가 최신인지 체크 후 사용자에게 최신상태 전달
웹캐시 교체 알고리즘
페이징 기법은 객체의 크기가 동일해 캐시부재(cache miss) 발생 시 로딩 비용이 균일하나 웹캐싱은 근원지 서버의 위치/특성에 따라 비용이 다르고 파일 단위의 캐싱이기에 캐싱 단위도 균일하지 않아 객체의 이질성을 고려해야 한다.
교체 알고리즘의 성능 평가 : 객체 i에 대해 ci는 인출비용, ri는 총 참조횟수, hi는 캐시 적중횟수, si는 객체의 크기, di는 서버로부터의 인출 지연시간이라 하자.
- 캐시 적중률(Hit Rate: HR) : 전체 요청 중 캐시에 적중되어 서비스된 요청의 비율 (∑hi∑ri)
- 비용 절감률(Cost-Savings Ratio: CSR) : 객체의 이질성을 고려한 비용까지 계산에 포함 (∑ci⋅hiri), ci 정의 방식에 따라 CSR은 BHR이나 DSR이 될 수 있다.
- 바이트 적중률(Byte Hit Rate: BHR) : ∑si⋅hiri
- 지연 감소율(Delay Savings Ratio: DSR) : ∑di⋅hiri
참조 가능성의 예측
- 아래 그림처럼 LRU, LFU는 성격에 따라 문제가 발생하는 케이스가 존재한다.
- 시간 지역성과 최근 참조빈도(인기도)를 고려함이 바람직하다.
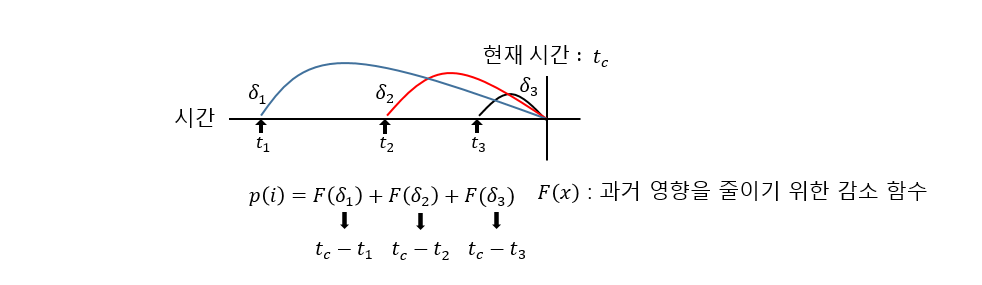
- LRFU(Least Recently Frequently Used) : 객체의 참조 가능성 계산 시 과거 참조 시점과 횟수 이용
- 시점 tc에서의 객체 i의 참조 가능성 P(i)=∑nk=1F(tc−tn)이다.
- F(x)는 감소함수이고 (12)λx (0≤λ≤1)로 정의
- λ=1이면 2n≥∑n−1i=12i에 따라 최근값만 반영되어 LRU로 동작
- λ=0이면 고정값으로 LFU로 동작
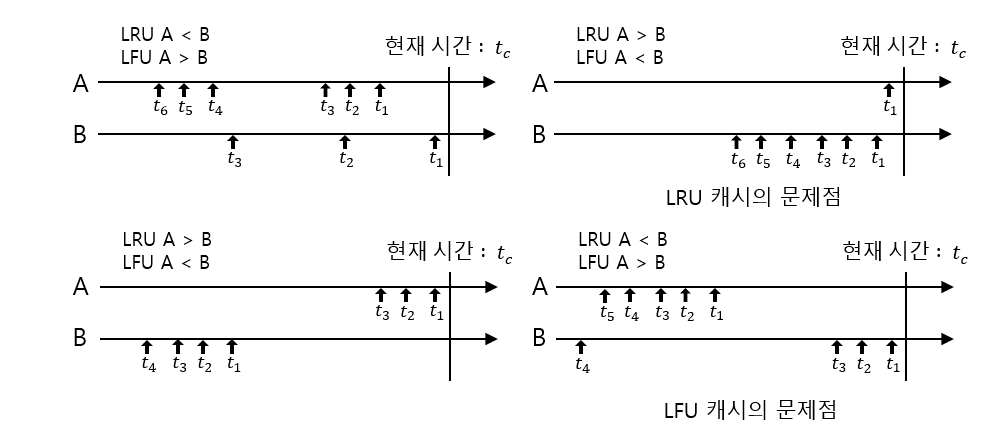
인기도를 반영할 때 노화(aging)기법을 적용해 캐시 오염 방지
- 캐시 오염 : 과거 참조가 많았다는 이유로 최근까지 불필요하게 유지된 상태
객체의 이질성 고려
- 캐시 적중률과 적중했을 때 절약되는 비용을 동시에 고려해야 함
- 대부분 알고리즘은 비용절감률이 최대 목적
캐시 교체 알고리즘의 시간복잡도
- 수십/수백만 개의 객체로 인해 적어도 O(log n)을 넘지 않아야 한다.
- LRU 캐시 알고리즘 : O(1), 이질성고려 X, 인기도 고려 X
- 대부분 힙 자료구조를 사용해 O(log n)으로 해결한다.
웹캐시의 일관성 유지 기법
- 약한 일관성 유지 : 캐싱된 객체가 변경되었을 가능성이 높은 경우에만 확인
- adaptive TTL : 객체의 최종 변경 시각과 최종 확인 시각을 고려하여 가능성 계산
- LMF로 판단하여 임계값 이상일 경우 근원지 서버에 확인 요청
- LMF=C−VV−M (C: 현재 시각, V: 최종 확인 시각, M: 최종 변경 시각)
- adaptive TTL : 객체의 최종 변경 시각과 최종 확인 시각을 고려하여 가능성 계산
- 강한 일관성 유지 : 반드시 최신 정보를 사용자에게 보장하기 위해 일일히 확인
- 일반적으로 오버헤드를 고려하여 약한 일관성 유지기법 채택
- polling-every-time : 객체에 대한 요청이 들어올 때마다 근원지 서버에 확인
- invalidation : 자신의 객체를 캐싱하는 모든 프락시 서버를 기록, 객체가 변경될 경우 통지
웹캐시의 공유&협력 기법
- ICP(Internet Cache Protocol) : 프락시 캐시들 간 웹객체의 검색/전송 지원
- cache miss 발생 시 동료 프락시에 ICP 질의를 멀티캐스트, 다른 캐시가 보유한 상태면 HTTP 요청 전송
웹캐시의 사전확인
- 웹캐시의 사전인출(Prefetching) : 웹 서비스의 응답 지연시간 감소를 위해 사용자가 아직 요청하지 않은 객체를 미리 받아오는 방식
- 예측 사전인출 : 웹페이지들 간 관계그래프 등을 구성해 참조될 확률 계산하여 사전인출 수행
- 대화식 사전인출 : 사용자가 HTML 문제에 대한 요청 시 HTML 코드 파싱하여 포함/연결된 웹 객체 사전인출
- 웹캐시의 유효성 사전확인 : 캐싱된 객체 참조 확률을 계산하여 미리 유효성을 확보, 요청 시 확인작업 없이 전송
관련 포스팅
1. 기술면접을 위한 OS 개념정리 01 - CPU 스케쥴링, 입출력 관리, 디스크 관리
'CS > OS' 카테고리의 다른 글
| 기술면접을 위한 OS 개념정리 04 - 프로세스 동기화, 데드락 (0) | 2021.08.22 |
|---|---|
| 기술면접을 위한 OS 개념정리 02 - 프로세스, 스레드 (0) | 2021.08.17 |
| 기술면접을 위한 OS 개념정리 01 - CPU 스케쥴링, 입출력 관리, 디스크 관리 (0) | 2021.08.16 |